I got on the web, got all the data hooked up and and built a simple browser interface that worked.
 |
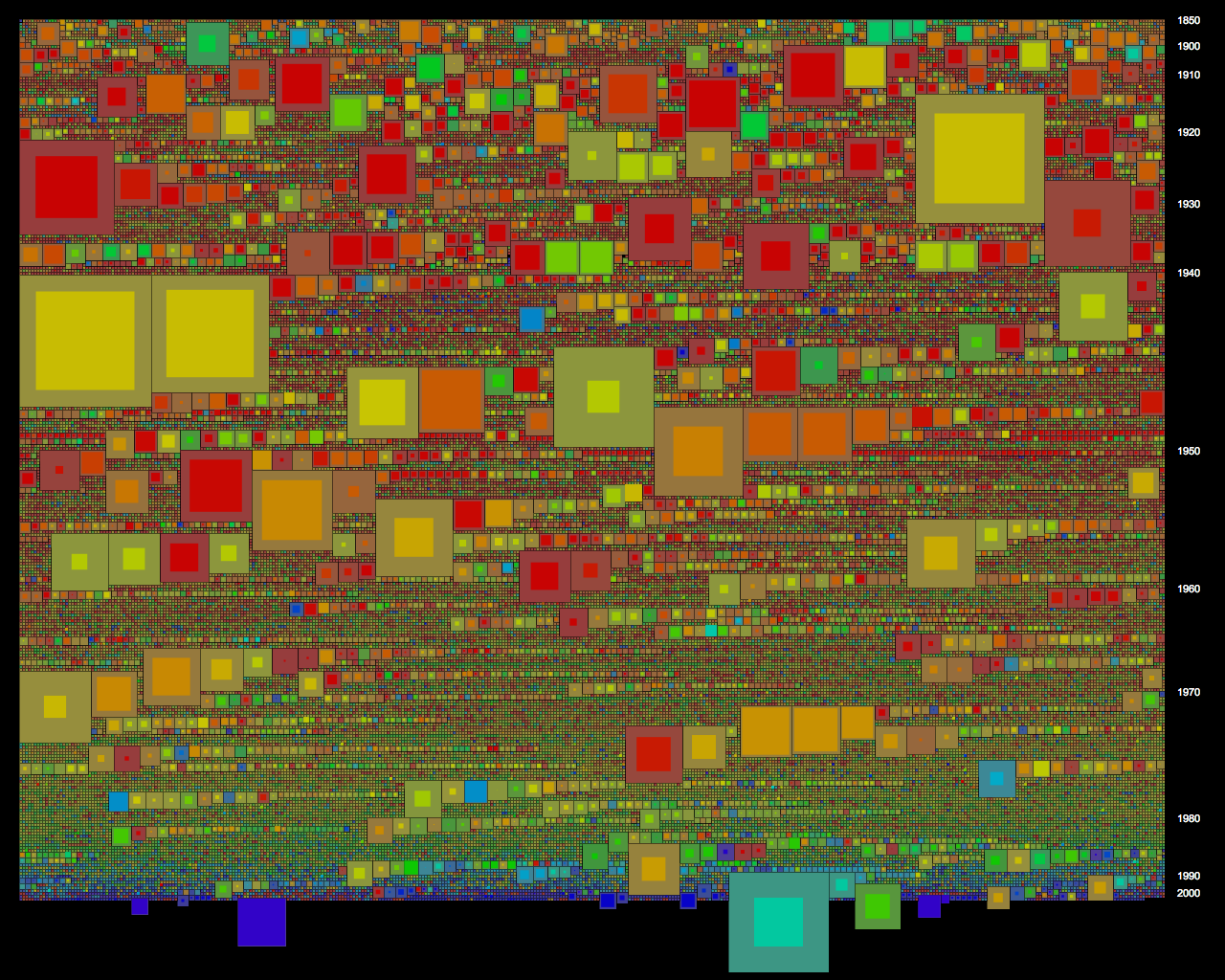
| NMA object browser - displaying drawing (right) in context of all drawings the NMA holds (centre) and all object types (left) |
On the left is a list of all object types, with counts, ordered by count. Clicking on an object type brings up all of the items of that type in the centre window. These are displayed as a thumbnail grid of images, or where images are not available as catalogue reference numbers (IRN) with truncated titles. Of course the preference would have been to have all images, but I felt it was important to include all items, and the truncated titles are still often informative and visually look ok.
Mousing over an item brings up the title in a popup box in the right corner. This is simply a div with a z-index to ensure it is on top of everything else. Upon mouse out, the popup div is removed using JQuery $.remove(). Easy. This was one issue to note - having to remember to do a mouse out as well as a mouse over function was a little tedious, although I can see it could be useful. It would have been nice if there was similar to in CSS, an additional mouse hover event - which I used to make links underlined when moused over. Using the CSS cursor propoerty, I was also able to make spans and divs look like <links> with the hand pointer.
The objects are sorted chronologically, using provenance date over associated date if both are available. Items without dates are retained, and placed at the end of the list. The year is displayed under the item image/title. Displaying as an inline histogram of sorts adds a rich contextual dimension - otherwise to find out dates one would have to zoom into an individual item record, and even then there would be no way of knowing how many other items were from the same year and what was the spread of years for items of that type. Thankfully the source data was in a consistent format with year first, and then day and month after if available, as a single string, which allowed for sorting a simple extracting of the first four characters using the JavaScript substr() method.
On the right a summary of an individual item record is displayed. The first item in the sorted list of object types is automatically loaded. Other items can be loaded by clicking on them in the display grid, or by clicking next/previous to cycle through the list. Mousing over the next/previous links also brings up the popup with title, as a preview. It was a critical design intention to keep the zoomed in display on the same screen as the full collection context, rather than in a pop up or new tab. The full record on the NMA catalogue is still linked to, for further information.
 |
| NMA object browser - mousing over a collection title highlights the objects within that collection |
There would be some easy extensions to this browser, which I would pursue if it was to be hosted on the NMA labs website - that is basically more links, more context. Clicking on a collection would bring up that entire collection in the browser centre window, and browse mode could be flipped to browse by collection, with all collections listed on the left. With the same architecture it would be easy to add other browse modes, such as material type, date or associated people.
So although I didnt get time to add all of this extra context, or refine further the browser interface, or draw some graph/visualisations, I am very glad that I challenged myself and built it to be native to the web. Once set up with data, the linking and mouse events work seamlessly. I feel like I could have fun linking up more and more and more, and am now ready to tackle some more websites!
I do think I could tidy up the code and data work a little. For example I forgot about global variables for much of the project and found myself getting convoluted in passing information to functions. I also could have prebuilt more of the lists, and done all the sorting, in Processing - to speed things up at the browser/client end.
That said, the next step really would have been to develop the NMA API to handle all the data calls, and this would allow the data to always be up to date. I wouldn't want to prebuild lists every month, when the NMA catalogue is added to.
Even if in a rudimentary form, I have established my confidence in showing everything in a big data set in a meaningful way. A great project to finish the Masters of Digital Design. Big thanks to Mitchell, and also to the National Museum for the privilege of working with this special data (which now must be wiped from our systems).